
Learning Garment Manipulation Policies toward Robot-Assisted Dressing
Paper links
ABSTRACT
Assistive robots have the potential to support people with disabilities in a variety of activities of daily living such as dressing. People who have completely lost their upper limb movement functionality may benefit from robot-assisted dressing, which involves complex deformable garment manipulation. Here we report a dressing pipeline intended for these people, and experimentally validate it on a medical training manikin. The pipeline is comprised of the robot grasping a hospital gown hung on a rail, fully unfolding the gown, navigating around a bed, and lifting up the user’s arms in sequence to finally dress the user. To automate this pipeline, we address two fundamental challenges: first, learning manipulation policies to bring the garment from an uncertain state into a configuration that facilitates robust dressing; second, transferring the deformable object manipulation policies learned in simulation to real world to leverage cost-effective data generation. We tackle the first challenge by proposing an active pre-grasp manipulation approach that learns to isolate the garment grasping area prior to grasping. The approach combines prehensile and non-prehensile actions, and thus alleviates grasping-only behavioral uncertainties. For the second challenge, we bridge the sim-to-real gap of deformable object policy transfer by approximating the simulator to real-world garment physics. A contrastive neural network is introduced to compare pairs of real and simulated garment observations, measure their physical similarity and account for simulator parameters inaccuracies. The proposed method enables a dual-arm robot to put back-opening hospital gowns onto a medical manikin with a success rate of over 90%.
Highlights
Learning six garment grasping/manipulation policies
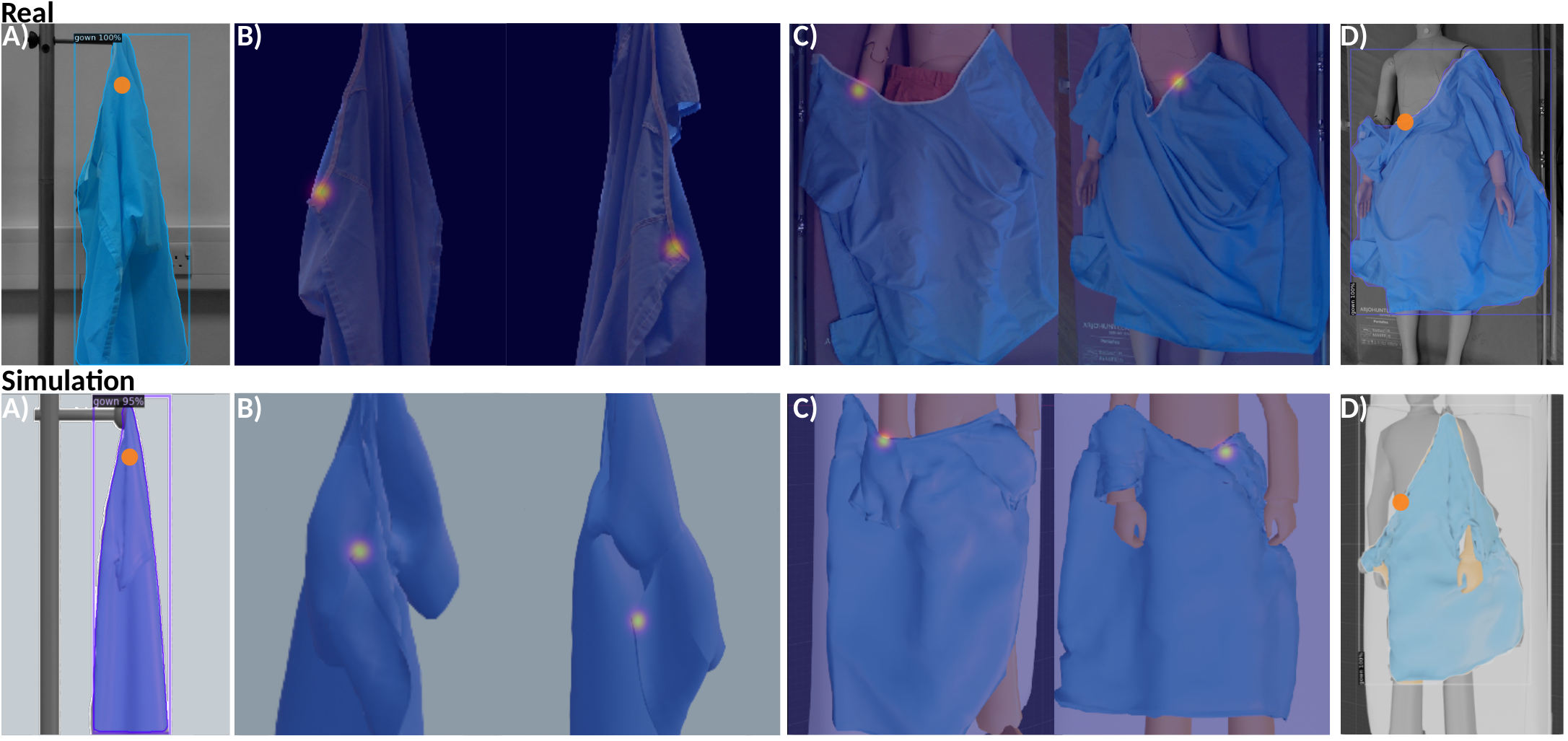
This work involves learning six grasping/manipulation points (orange dot/heat map) on the garment to achieve the dressing pipeline in real-world (Top) and simulation environments (Bottom). (A) The grasping point in stage A for picking up the garment on the rail, chosen randomly to be near the hanging point on the segmented garment. (B) Two manipulation points in stage B for fully unfolding the garment in the air, localized by our proposed active pre-grasp manipulation learner along with their manipulation orientations and motion primitives. (C) Two grasping points in stage C for upper-body dressing, learned by pixel-wise supervised neural networks. (D) The last grasping point in stage D for spreading the gown to cover upper body, chosen randomly to be near the collar on the segmented garment.
The framework of the dressing pipeline
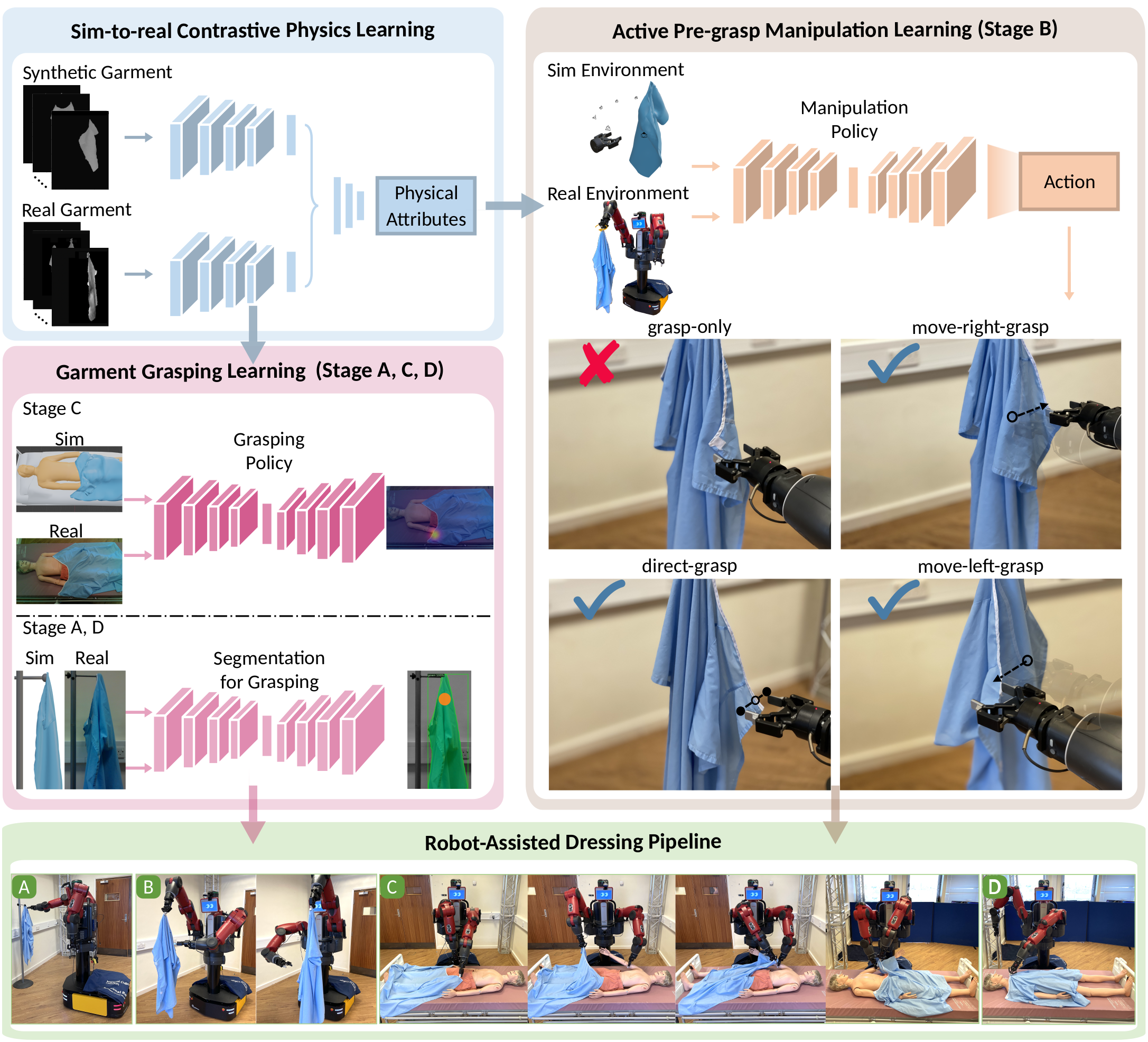
For each grasping/manipulation policy learning, simulation with learned garment physics using the proposed contrastive learning approach is leveraged to either generate cost-effective labeled data for neural network training (stage A, C, D), or learn the proposed pre-grasp manipulation policy directly in simulation before transferring to real systems (stage B).
Acknowledgment
Funding: This research is financially supported in part by a Royal Academy of Engineering Chair in Emerging Technologies to Professor Yiannis Demiris, and in part by UKRI Grant EP/V026682/1.